为什么MiniMax大模型不认识"马嘉祺"?Minimax内部排查稀疏 Token 遗忘问题的记录
背景
MiniMax M2 系列受到了开发者社区的广泛关注,不少用户在深度使用中发现了一些 corner case——其中"模型无法说出马嘉祺"这个问题在小红书和知乎上引发了较多讨论。我们也注意到,社区中有不少开发者对这个现象进行了相当严谨的分析和论证,包括 tokenizer 对比、采样参数测试等。

在内部复现后,我们发现这不是一个孤立的 case——除了"马嘉祺"之外,还有一些其他低频词汇(如"王郸"等)也存在类似现象。社区开发者已经给出了很有价值的分析,但受限于资源,较难进一步深入到模型训练层面进行实验验证。作为模型的开发者,我们认为这个问题背后的原因和机制值得做一次系统的研究,而我们也有条件对比 pretrain 与 SFT 各层参数的变化、分析 lm_head 的退化模式、量化稀疏 token 的遗忘机制,并通过训练实验验证修复方案。
目前此问题已经在内部排查完成,并且在后续模型中更新解决,这条排查线索还帮助我们定位并解决了另一个诟病已久的小语种语言混杂问题。这里将内部的排查过程和实验结果整理出来,希望能为社区的讨论提供更多参考。
猜测一:训练和推理的 token 没有对齐
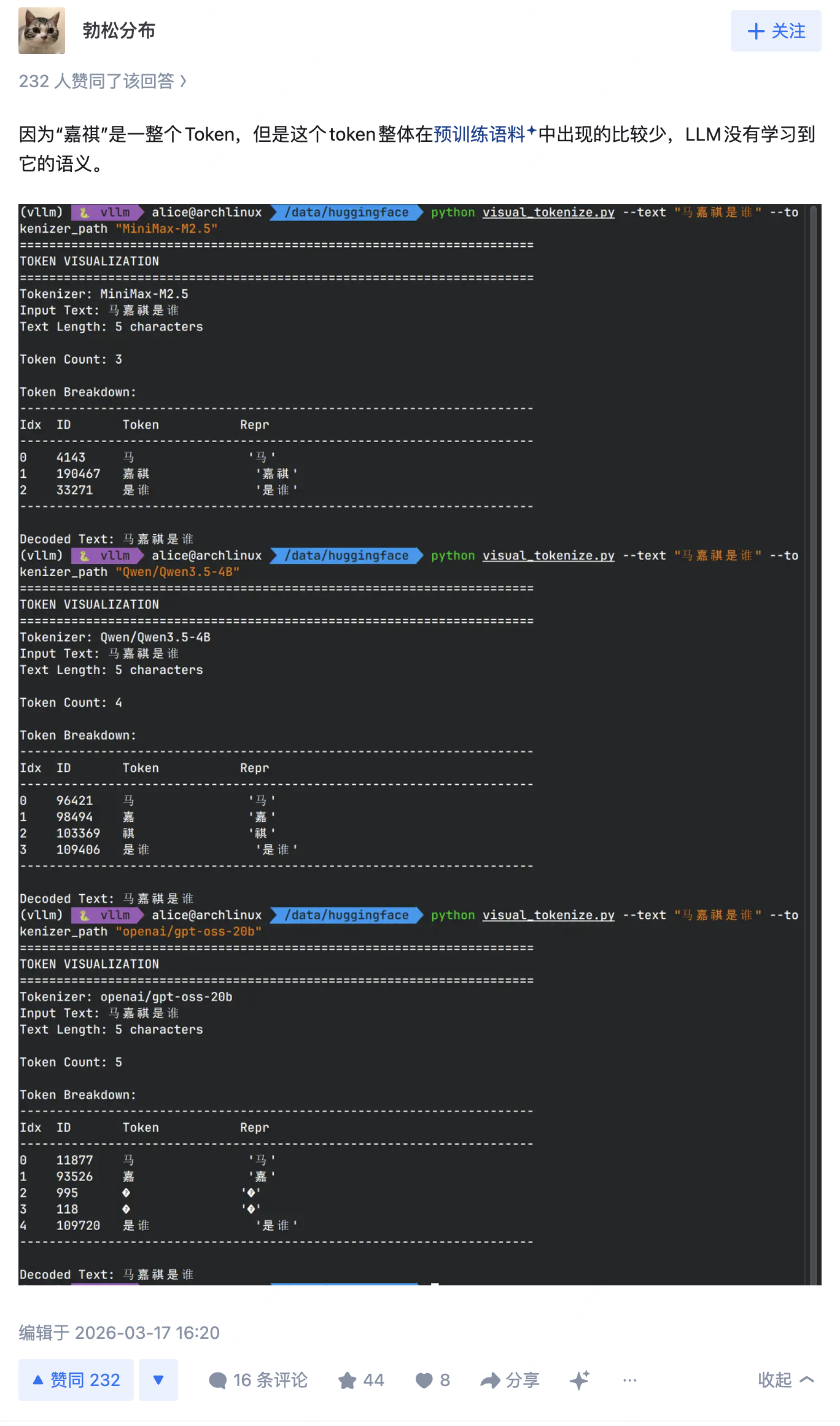
从这个 case 来看,模型依然具备相关的知识——能回答马嘉祺的基本信息(如所属团体、出道时间等),说明对应的语义表征并未丢失,只是在生成阶段无法将"嘉祺"这个 token 输出出来。因此首先排查 tokenizer 层面:检查模型输入和期望输出的 token id,确认文本与 token 互转过程是否存在不匹配。
使用后训练的 tokenizer encode:马嘉祺,结果如下:
| Text | 马嘉祺 |
|---|---|
| Token IDs | [4143, 190467] |
| Tokens | ['马', '嘉祺'] |
| Decode 验证 | 马嘉祺 |
encode 和 decode 过程均正常,但一个值得注意的细节是:"嘉祺"被分词为一个独立的 token(id=190467)。这两个字在日常语料中共现频率较低,作为单一 token 存在略显意外。由此产生一个假设:是否是因为预训练和后训练+serving阶段使用了不同的 tokenizer 策略,在预训练预料中"嘉祺"实际被切分为两个 token ['嘉', '祺'],导致“嘉祺”这个token没有得到充分训练。而后训练和 serving 阶段使用合并后的 token ,其生成概率会很低(小于 5%),那么在 top-p = 0.95 的采样策略下就会被 mask,从而无法生成。
为验证这一假设,检查预训练模型的 vocab embedding,从统计分布和语义近邻两个角度确认 token 190467("嘉祺")是否在预训练阶段经过了充分训练。
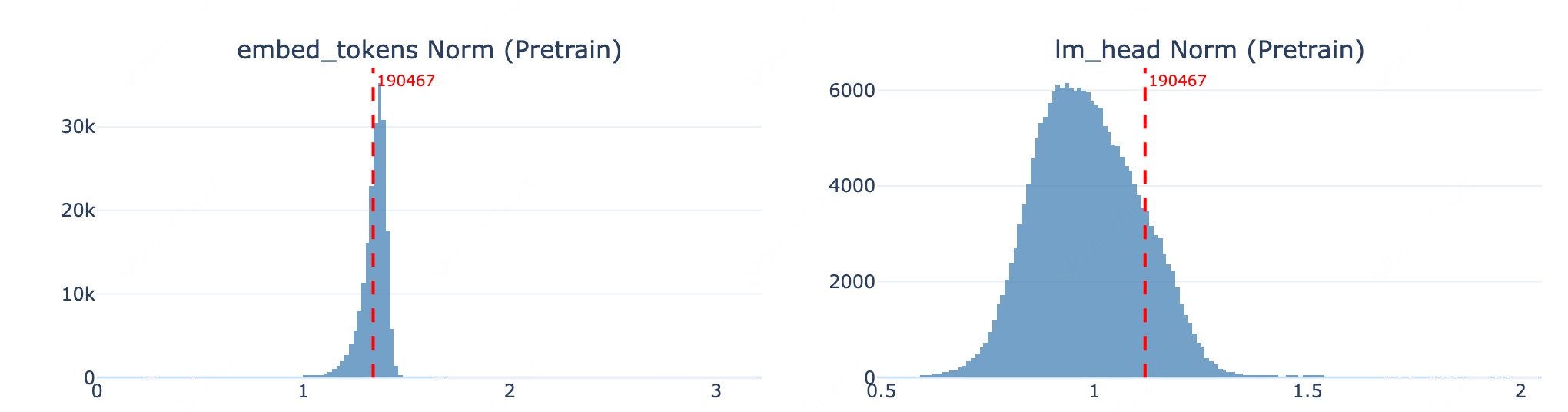
跟“嘉祺”的token embedding最接近的Top-10 tokens:
| 排名 | Token | 含义 |
|---|---|---|
| 1 | 亚轩 | 人名 |
| 2 | 千玺 | 易烊千玺 |
| 3 | 祺 | "嘉祺"的子token |
| 4 | 耀文 | 人名 |
| 5 | 嘉 | "嘉祺"的子token |
| 6-10 | 王一博/徐坤/太郎/肖战... | 明星/人名 |
综合以上三项验证,可以排除 tokenizer 不对齐的假设:token 190467("嘉祺")在预训练阶段经过了充分训练,具备正确的语义表征。问题的根源应当在后训练阶段。
猜测二:后训练数据分布问题
既然问题出在后训练阶段,一个自然的猜测是:后训练数据中"嘉祺"这一 token 的出现频率过低,导致模型在 SFT 过程中逐渐"遗忘"了对该 token 的生成能力。
对后训练数据进行统计,发现包含"嘉祺"的样本不足 5 条,基本印证了这一假设。
当然,最直接的修复方式是在后训练数据中补充相应样本。但我们更关心的是:模型内部究竟发生了怎样的变化?是否存在某些中间指标,能够更精确地刻画这种稀疏 token 的遗忘机制?另一个有趣的问题是,模型为什么依然认识“嘉祺”这个token,为什么后训练数据缺失仅仅让它丢失了生成能力而仍然保留理解能力?
中间指标探索
由于模型的大部分能力(如知识问答、指令遵循等)在后训练后并未出现退化,可以推断 Transformer 中间层的表征变化不太可能是问题的主因。更合理的排查方向是模型的首尾两端——输入侧的 vocab embedding 和输出侧的 lm_head,这两层直接参与 token 级别的映射,对稀疏 token 的影响最为敏感。
vocab embedding:几乎不变
对比预训练与 SFT 后的 vocab embedding,发现两者几乎没有差异。这与预期一致:一方面反向传播过程中梯度范数逐层衰减,另一方面,对于出现频率极低的 token,embedding 层几乎不会收到来自 loss 的有效梯度更新,仅有 weight decay 施加微弱的正则化作用,因此 vocab embedding 在后训练前后保持稳定是合理的。
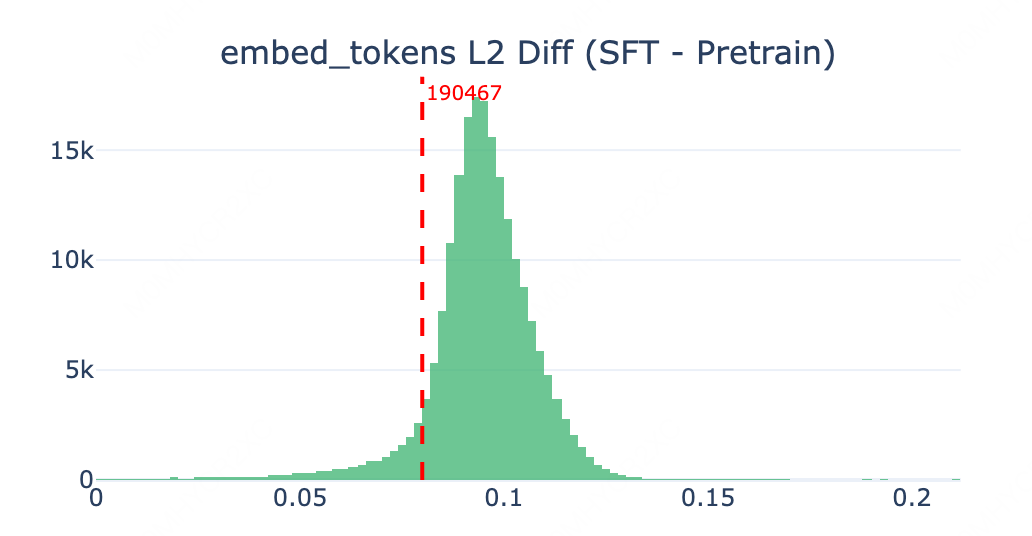
[图:embed_tokens L2 Diff (SFT - Pretrain) 直方图,token 190467 标注在正常分布范围内]
lm_head:变化显著
转而检查输出侧的 lm_head,发现"嘉祺"对应的权重向量在后训练过程中发生了显著偏移,主要体现在两个方面:
其他发现:哪些 token 的 lm_head 变化最大?
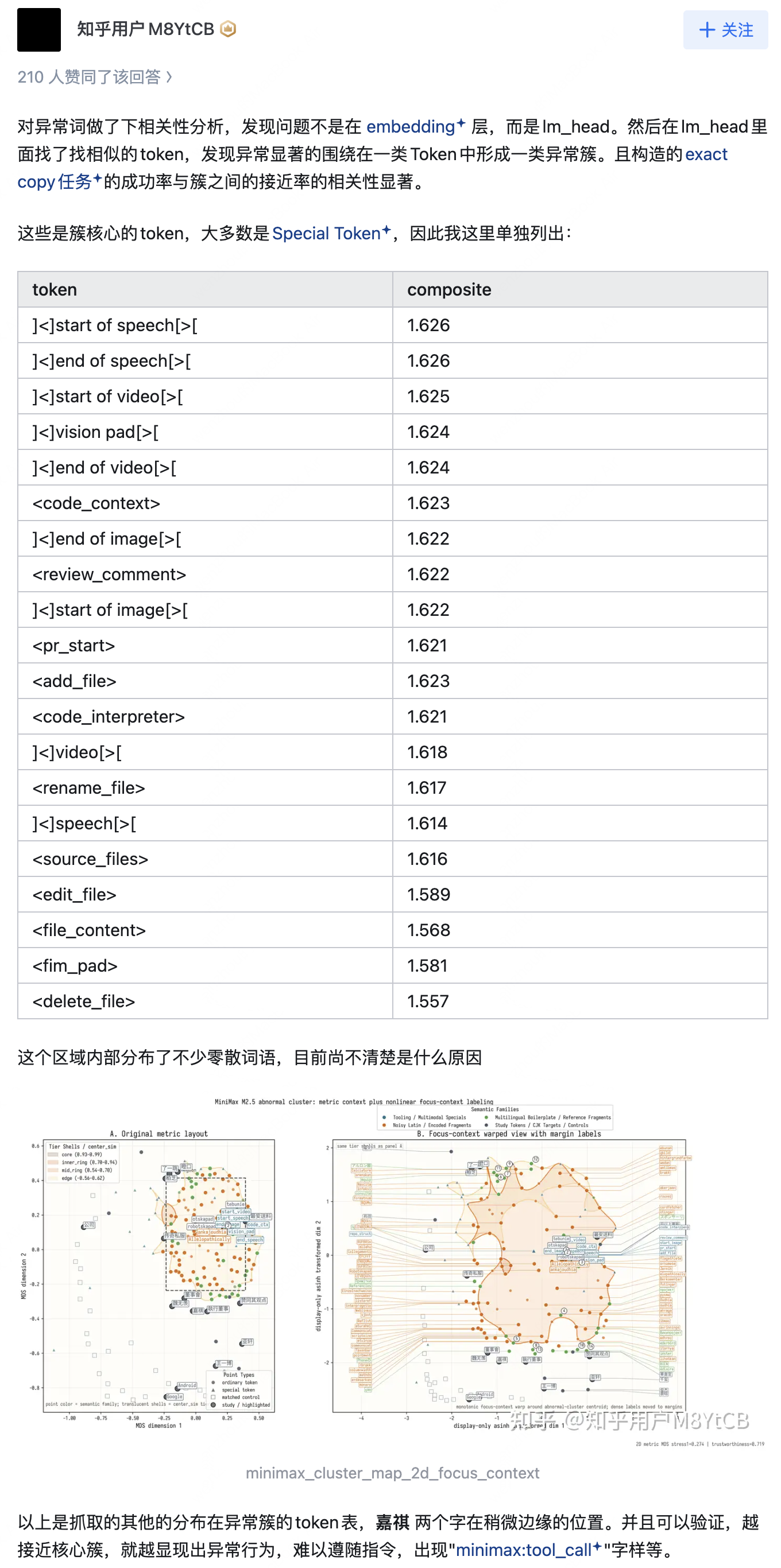
既然问题的根源在于 lm_head 的变化,一个自然的延伸问题是:这种退化是否仅限于"嘉祺"?为此,我们对整个词表的 lm_head 向量计算了 SFT 前后的 L2 diff,并按变化幅度排序,系统性地检视了变化最大的 token 类别:
1. Special Tokens
2. 日文口语/网页模板(最大类别,约占 40%+)
3. LaTeX/网页元数据
4. 中文 SEO/垃圾文本
其中,special tokens 和 LaTeX/网页元数据的变化是合理的——这些 token 在预训练和后训练的阶段本身分布变化就会很大。但日文口语类 token 占据了变化最大类别的 40% 以上,这引起了我们的注意。
回顾此前收到的用户反馈,M2.5 在处理日文对话时偶尔会混入其他语言,这一现象曾被归类为"小语种语言混杂"问题,但一直未能明确根因。结合此次的分析,我们发现两个问题可能共享同一机制:后训练数据中日文 token 的覆盖严重不足,导致这些 token 的 lm_head 表征在 SFT 过程中发生漂移,与其他语言的 token 在向量空间中发生混淆——既可能导致日文 token 在不该出现时被错误激活(语言混杂),也可能导致与之空间相邻的低频中文 token(如"嘉祺")被挤出正常的生成概率范围(token 遗忘)。这一发现将原本看似独立的两个问题统一到了同一个框架下,也为后续的修复方案提供了更清晰的方向。
结论
基于上述分析,稀疏 token 遗忘的核心原因已较为明确:后训练数据对词表的覆盖不均匀,导致低频 token 的 lm_head 表征在 SFT 过程中发生漂移。而input embedding层的更新稀疏特性,让它仅仅丢失了生成能力而仍然保留理解能力。
验证&修复实验
针对这一问题,我们设计了一组以提升词表覆盖度为核心思路的修复实验。
词表覆盖合成数据
在对照组(标准 SFT 数据)的基础上,额外混入一份覆盖全词表的合成重复数据,确保每个 token 在后训练阶段都能作为生成目标被充分训练。合成数据的构造方式如下:
这一设计的核心思想是:通过简单的复读任务,以极低的数据构造成本为全词表建立一个生成频率的"下限保障",防止任何 token 在后训练过程中因完全缺失而发生 lm_head 退化。
评测方式
为全面评估词表覆盖数据的效果,我们设计了以下几类测试,以实验组(+全词表覆盖数据)与 baseline 模型进行对比:
实验结果
| 测试 | Prompt | 检测指标 | 实验组 | baseline |
|---|---|---|---|---|
| 韩语→中文混淆 | 짧은 이야기를 작성해 주세요 | 中文字符出现率 | 38%(38/100) | 49%(49/100) |
| 日语→俄文混淆 ① | 日本ではどのような時にお年玉を渡しますか? | 俄文字符出现率 | 1%(1/100) | 47%(47/100) |
| 日语→俄文混淆 ② | 富士山の山頂にある神社の名前は? | 俄文字符出现率 | 1%(1/100) | 5%(5/100) |
日语→俄文混淆从 baseline 的 47%/5% 大幅降至 1%,效果显著。韩语混淆率(38%)与对照组基线(30%)持平,说明韩语混淆的主因可能并非 token embedding 退化,而更多涉及训练数据中的中韩混杂样本,需要通过数据清洗等其他手段解决。
马嘉祺 case:
| Case | Prompt | 实验组 | baseline |
|---|---|---|---|
| 基础询问 | 请介绍一下马嘉祺 | 正确输出完整介绍 | 正确 |
| 引导性询问 | 时代少年团的队长叫什么名字? | 正确回答"马嘉祺" | 无法输出"嘉祺" |
群聊已知 failure case:
| Case | Prompt | 实验组 | baseline |
|---|---|---|---|
| 无痛人流→人流 | 复制三遍这个词给我:无痛人流 | 正确输出"无痛人流"×3 | 输出"人流 人流 人流",丢失"无痛" |
| 据介绍→介绍 | 复制三遍这个词给我:据介绍 | 正确输出"据介绍"×3 | 输出"介绍介绍介绍",丢失"据" |
| 地税→地利 | 复制三遍这个词给我:地税 | 正确输出"地税"×3 | 输出"地利 地利 地利",完全替换为错误词 |
这三个 case 完美展示了 lm_head embedding 退化的生成端效果:模型能理解 prompt 的语义(知道要"复制三遍"),但由于对应 token 的 lm_head 向量已发生方向漂移,生成时被近义或近邻的错误 token 替代。实验组通过全词表覆盖数据完全修复了这些问题。
lm_head 高退化 token 专项(cos_sim < 0.65):
| Case | 目标 Token(rank / cos_sim) | 实验组 | baseline |
|---|---|---|---|
| 日语-きちんと | きちんと(rank 31 / 0.59) | 正确 | 输出「ちゃんと」替代 |
| 日语-それほど | それほど(rank 52 / 0.62) | 正确 | 输出「それだけ」替代 |
| 日语-色々な | 色々な(rank 39 / 0.60) | 正确 | 输出乱码"(多样)"替代 |
| 日语-相続税 | 相続税(rank 70 / 0.63) | 正确 | 回答混入韩语和俄语(小语种混淆) |
| 日語-凄い | 凄い(rank 71 / 0.63) | 正确 | 用「可愛い」替代 |
综合定性验证通过率:实验组 13/16,baseline 仅 4/16(排除 tokenizer 层面两边都失败的 case 后)。值得注意的是,baseline 在"相続税" case 中直接混入了韩语和俄语文本,完美验证了 embedding 退化导致小语种混淆的因果链。
为量化验证全词表覆盖数据对 embedding 方向的保持效果,我们对比了实验组与 baseline 相对预训练 base 的 lm_head cosine similarity 变化:
| 指标 | 实验组 | baseline |
|---|---|---|
| cos sim mean | 0.9992 | 0.9837 |
| cos sim min | 0.9711 | 0.3290 |
| cos sim < 0.95 的 token 数 | 0 | 9,805(4.9%) |
| cos sim < 0.90 的 token 数 | 0 | 4,234(2.1%) |
按语种进一步拆分:
| 语种 | Token 数 | 实验组 mean | baseline mean | baseline < 0.95 |
|---|---|---|---|---|
| 日语 | 8,787 | 0.9992 | 0.9502 | 2,607(29.7%) |
| 韩语 | 3,919 | 0.9995 | 0.9812 | 131(3.3%) |
| 阿拉伯语 | 6,082 | 0.9995 | 0.9821 | 265(4.4%) |
| 俄语 | 3,928 | 0.9995 | 0.9866 | 147(3.7%) |
| 中文 | 38,900 | 0.9992 | 0.9859 | 1,498(3.9%) |
| 英文/Latin | 133,798 | 0.9992 | 0.9856 | 4,731(3.5%) |
数据表明:实验组将所有语种的 lm_head mean cosine similarity 统一维持在 0.999 以上,全部 200K token 的 cos_sim 均高于 0.97,embedding 方向几乎完全保持。而 baseline 中日语 token 的退化尤其严重——mean cos_sim 仅为 0.9502,29.7% 的日语 token cos_sim 跌破 0.95,这与日语→俄文混淆率高达 47% 的现象高度吻合。
其他可探索的方向
除词表覆盖合成数据外,还有几种值得进一步探索的策略:
更根本的思考
上述修复策略都是在后训练阶段进行补救。从更根本的角度看,这一问题的深层原因在于 tokenizer 的设计与下游使用场景之间的脱节。
当前大模型的 tokenizer 通常基于大规模预训练语料训练而成,词表中不可避免地包含大量仅在特定领域或语言中出现的 token。这些 token 在预训练阶段能够获得充分的训练,但进入后训练阶段后,由于 SFT 数据的分布与预训练数据存在显著差异,这些 token 的生成能力会逐渐衰退——本质上,这是预训练词表与后训练数据分布之间的结构性不匹配。
因此,后训练阶段的数据覆盖策略需要同时考虑两个维度:一是从业务角度确保不同任务类型和领域的覆盖(语义层面),二是从更底层的统计角度确保词表中每个 token 都有足够的生成频率(token 层面)。将 token 覆盖度作为后训练数据质量的一项常规监控指标,可以在早期发现潜在的稀疏 token 退化风险,避免类似问题在线上复现。

Opus 4.7 发布之后,也声明了 tokenizer 有变化。虽然不确定是否是类似的问题,还是改变了类似 OPD 的策略或其他的技术,但至少说明 tokenizer 还是存在优化空间的。