MiniMax M3:前沿 Coding 能力,1M上下文,原生多模态,一个模型全给你
MiniMax M3 今日正式发布。
MiniMax M3 在编程和智能体等专业任务上达到了前沿的能力。它使用了我们提出的全新注意力架构 MSA (MiniMax Sparse Attention ),最高支持 1M 超长上下文。 如外界所期待的那样,它也是一个原生多模态模型,支持图片和视频的输入,并能操作电脑桌面。
这三种能力是海外闭源前沿模型所必须拥有的。M3 是国内第一个齐备这些要素的模型,也是目前唯一的开源模型。
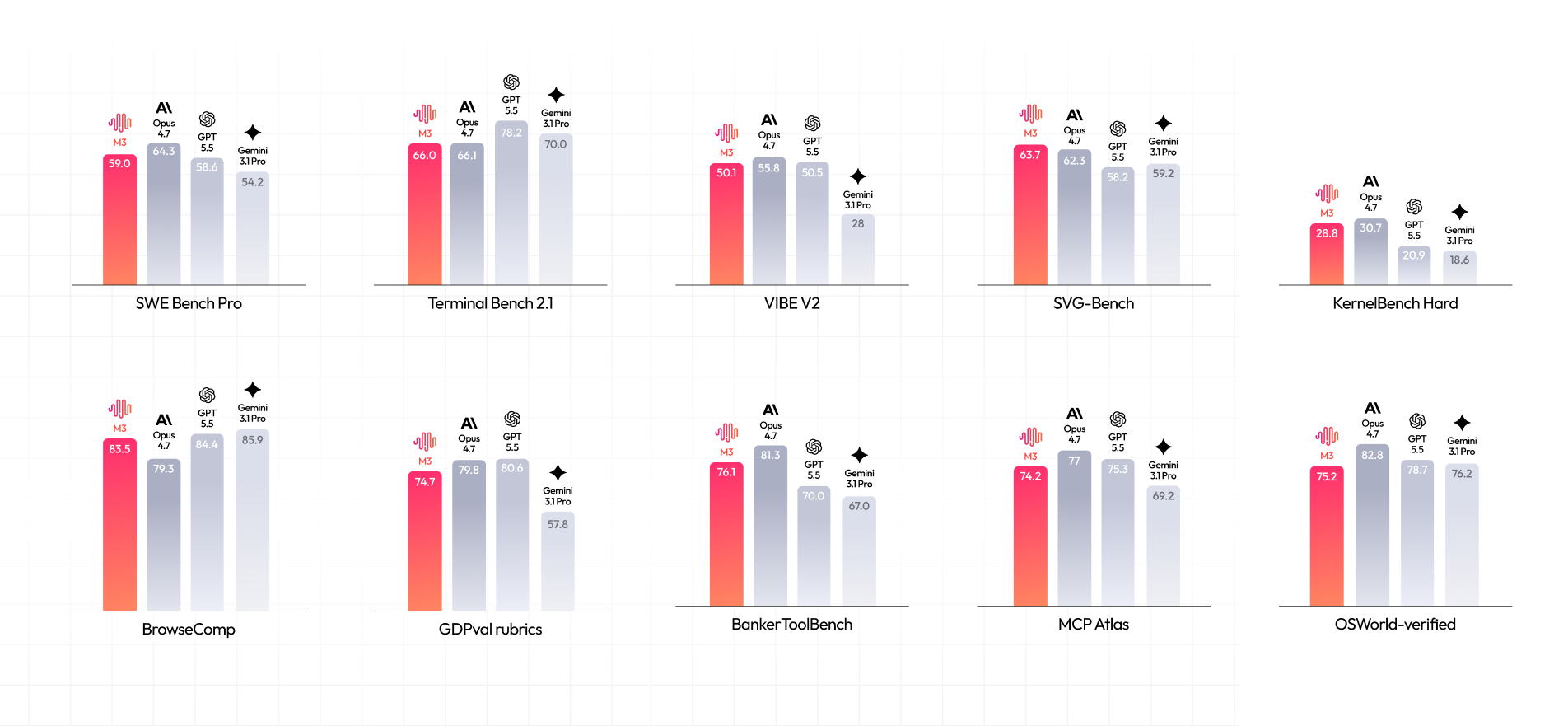
在 Coding 能力方面,M3 相比 M2 显著增强,在 bugfix、前后端、性能优化等方面均接近海外闭源模型。
在 Agentic 能力方面,M3 在办公常用的搜索、Office 能力上表现突出,并在金融领域变得初步可用。
你可以在 MiniMax Code, Token Plan 和我们的 API 服务中第一时间体验到 MiniMax M3。
MSA:结构创新带来 Context Scaling
在设计 MiniMax M3 模型时,解决更复杂的 Agent 任务是它最重要的目标之一,而其中最大挑战就包括 context scaling。要实现真正的改变,必须从最底层的注意力机制入手,避开全注意力机制计算复杂度平方级增长的“先天缺陷”。
MSA 是一个简洁且易于扩展的全新稀疏注意力架构,它给 M3 带来了 1M 的上下文窗口,并让 context 真正成为又一个可被 scale 的维度。
稀疏注意力机制普遍通过增加一个初筛阶段来避免复杂度爆炸问题。与 DSA 和 MoBA 等方案相比,MSA 可以更精确为 KV 分块,实现更高的有效上下文覆盖。
同时,我们还在算子层直接优化,采用以 KV 块为外层来聚合命中 query 的 KV outer gather Q。每块只读一次、访存连续,在 M3 的 head 配比下计算访存比显著优于通行方法,比开源的 Flash-Sparse-Attention、flash-moba 快 4 倍以上。
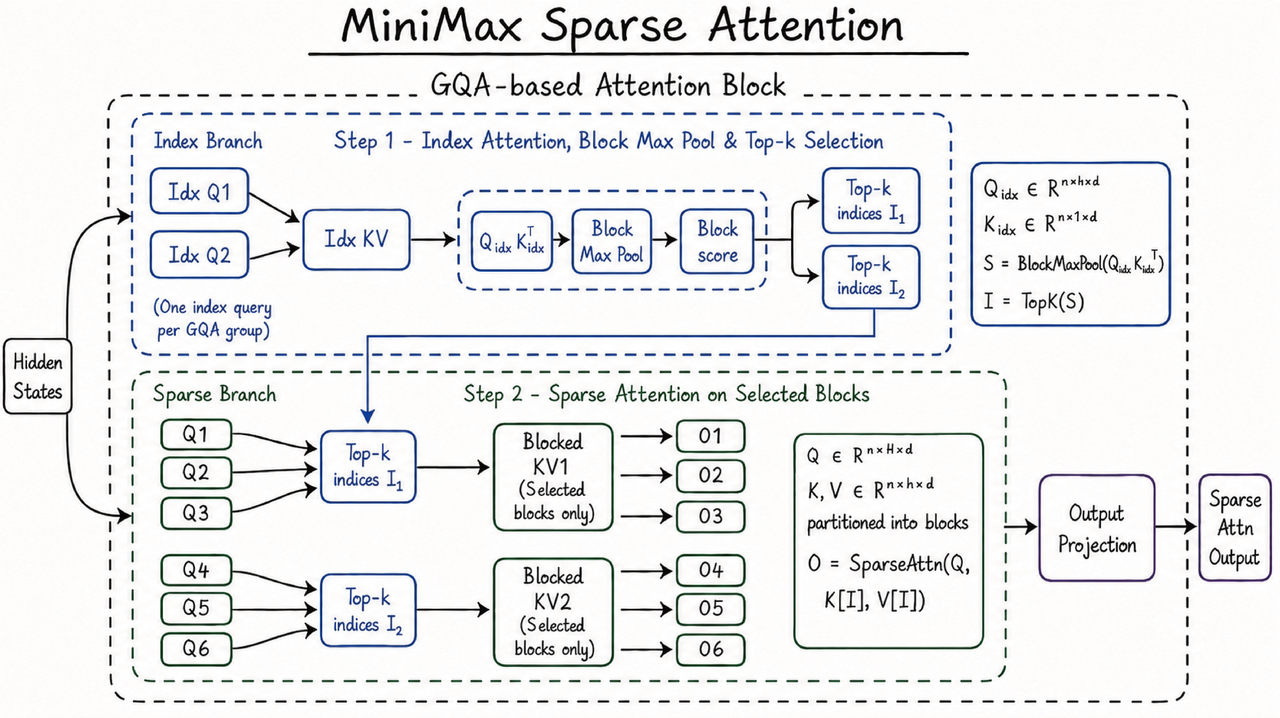
简洁可扩展、易于实现且硬件友好的特点,使它的理论收益能真正落地:在 100 万上下文下,M3 每 token 计算量仅为上代模型的 1/20。在 prefilling 阶段,我们实现了超过 9 倍的加速倍率,在 decoding 阶段有超过 15 倍的加速优势。而且在多个对照实验中,MSA 的绝大部分能力与全注意力打平。
前沿的 Coding 和 Agentic 能力
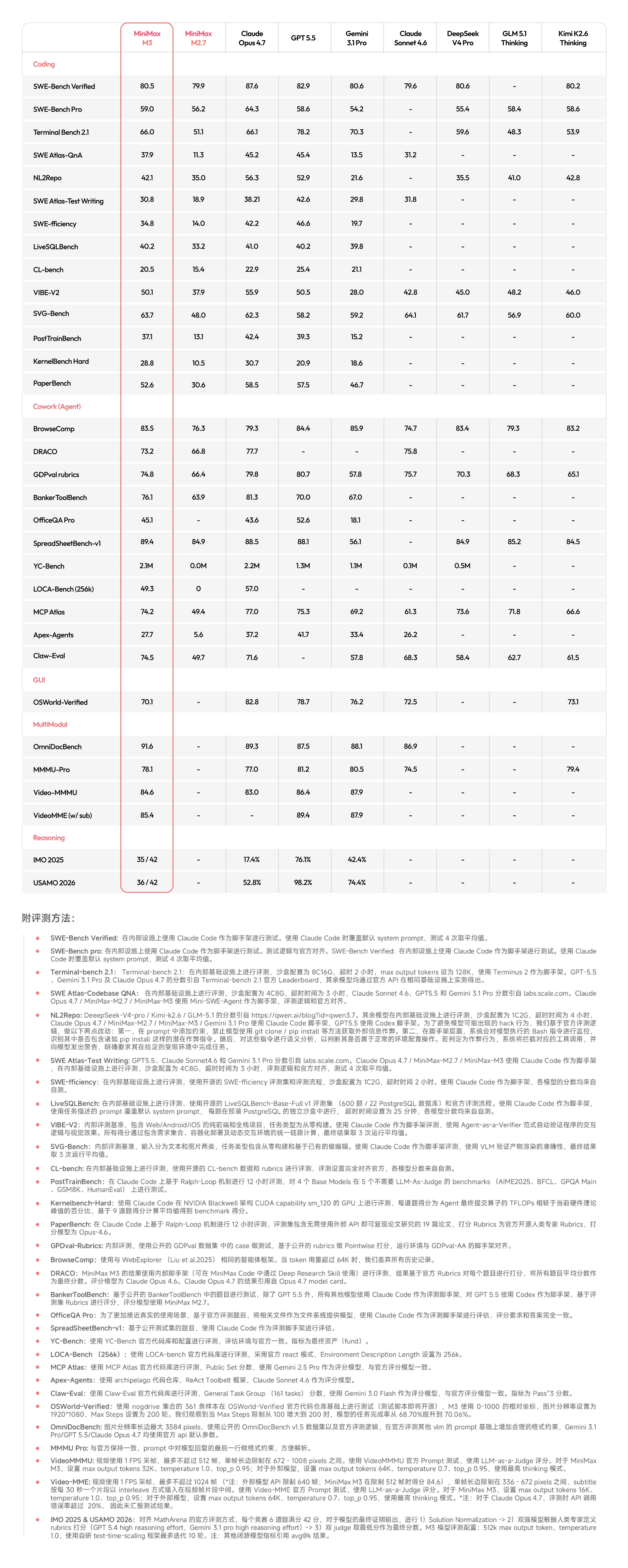
Coding 与 Agent 能力是 M3 重点提升之处,在涵盖软件工程、终端执行等多个维度的国际权威评测中,M3 均达到国际领先水平:
- SWE-Bench Pro: 59.0%
- Terminal Bench 2.1: 66.0%
- SWE-fficiency: 34.8%
- KernelBench Hard: 28.8%
- MCP Atlas: 74.2%
今天的 Coding 能力越发取决于能否用真实世界的用户逻辑来训练模型。这意味着仅靠现有 Coding Benchmark 难以完整刻画真实用户体验。
当前大多数代码 Agent 的训练与评测,都建立在单轮任务(single-turn task)的假设之上。但真实使用场景并非如此。用户往往会在同一个 Session 中持续协作:不断澄清需求、调整方案、交叉派发任务,并根据中间结果进行多轮迭代优化。
为了缩小 Benchmark 与真实使用体验之间的差距,我们构建了交互式用户模拟器框架。
它通过模拟真实开发者在协作过程中的行为模式,让模型在训练和评测阶段就接触到更加接近生产环境的交互场景。该框架能够模拟需求补充、方案讨论、反馈修正、连续任务切换以及复杂项目迭代等行为,使 Agent 不再只是被动执行指令,而是能够主动与用户协同完成任务。
下一代 Agent Coding 比的不仅是代码生成,更要比拼长期协作能力、规划能力以及人与 Agent 的协同效率。M3 把真正对 Coding 和 Agent 至关重要的数据 Scale up,目标不仅是在 Benchmark 上取得领先,更是在真实研发流程中成为开发者可靠的协作伙伴。
多模态:原生训练,继续 Scale
M3 是一个从 Step 0 开始进行多模态混合训练的模型。这种原生多模态的路线能让不同模态数据的语义空间更天然、更高度的融合。
同时,我们的大量实验显示,Interleaved data(交错数据)相比合成类数据更容易 scale(扩展)。因此,在 M3 周期,我们重构了整套文本的预训练数据管线,产生大量的 interleaved data,并将其用在模型的训练中。
实际任务
在我们内部对 M3 的使用和测试中,多个实际任务给我们留下深刻印象。
论文独立复现
作为一个前沿模型必须具备的三个能力,我们想看看 1M 超长上下文、顶级的编程和 agent 能力,以及原生多模态能力同时发挥作用在长线程里解决一个复杂任务的表现。
我们丢给 M3 一篇 ICLR 2025 Outstanding Paper Award 获奖论文——Learning Dynamics of LLM Finetuning,让它独立复现。这篇论文研究的是大语言模型微调过程中的“学习动力学”。最终 M3 自主运行了接近 12 小时,全程自主产出 18 次 commit 与 23 张实验图表,并跑通了核心实验:
不仅成功吻合了 SFT 阶段的预测概率变化趋势,清晰观测到 DPO 实验重点讨论的 squeezing 效应,还顺利验证了原论文提出的 Extend 缓解方法。
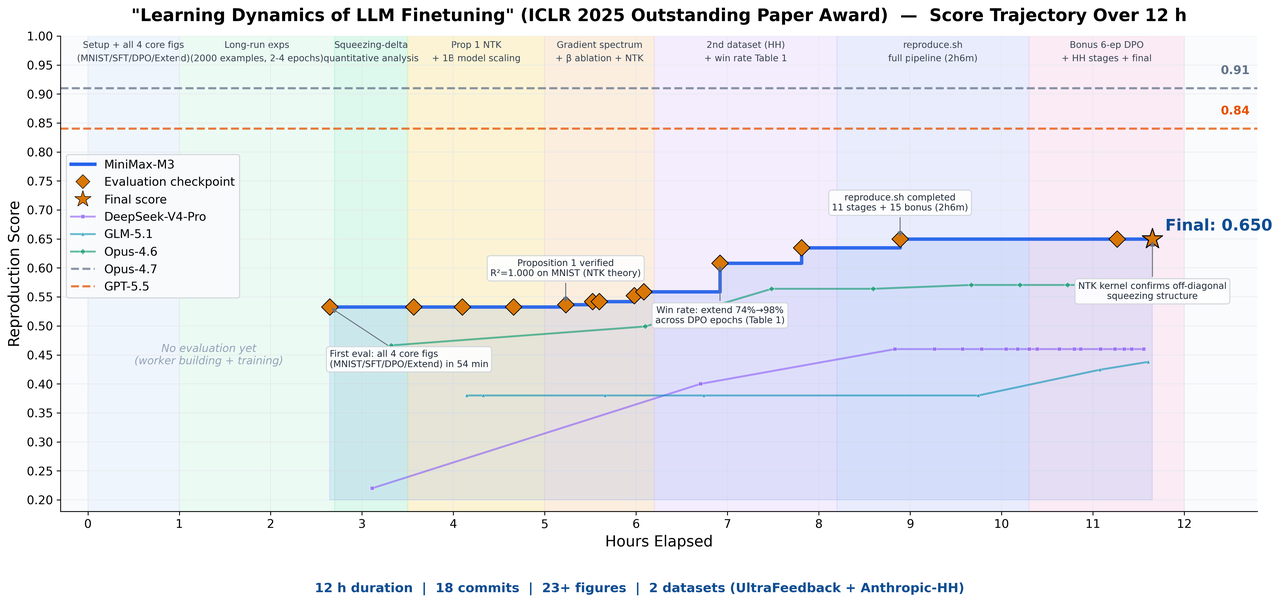
这个过程里,需要多模态能力来看懂论文里的曲线图、数据、公式,而长上下文保证了论文 + 代码 + 实验日志可以一次性进窗口,编程 + agent 的能力足够强,才能长线程甚至并发地完成复现。
M3 都做到了。
CUDA 算子优化
FP8 矩阵乘(GEMM)是大模型推理中计算量最集中的环节之一,也是优化难度最高的环节之一。工程师必须同时处理数据排布、计算流水线调度、硬件特性适配等多层相互耦合的问题。在 NVIDIA Hopper 架构 GPU 上手写一个生产级的 FP8 GEMM kernel,通常需要资深团队 1–2 周的集中投入。
我们以此检验 M3 的长程自主迭代能力。我们要求 MiniMax M3 在 NVIDIA Hopper 架构 GPU 上优化该 kernel,模型的起点仅有一份任务描述、一个 benchmark 评估脚本、一个无法直接运行的 Triton 骨架,没有任何 reference 高性能实现可供参考。这意味着模型不能通过模仿已有方案来走捷径,必须从基本原理出发,自主探索优化路径。
在随后约 24 小时的连续执行中,M3 共完成 147 次 benchmark 提交、1959 次工具调用,完全自主地走完了从 baseline 实现到生产级优化的全部路径,包括 baseline 实现、autotune 配置生成、性能瓶颈诊断、CUDA Graph 集成、persistent kernel 重写、host 端调度优化等,每一步都通过 benchmark 反馈进行自我验证,无需人工介入。
最终 M3 经过 6 轮标志性优化,将 Hopper FP8 硬件峰值利用率从首版 7.6% 推进至 71.3%,实现相较于原始版本的 9.4× 加速。
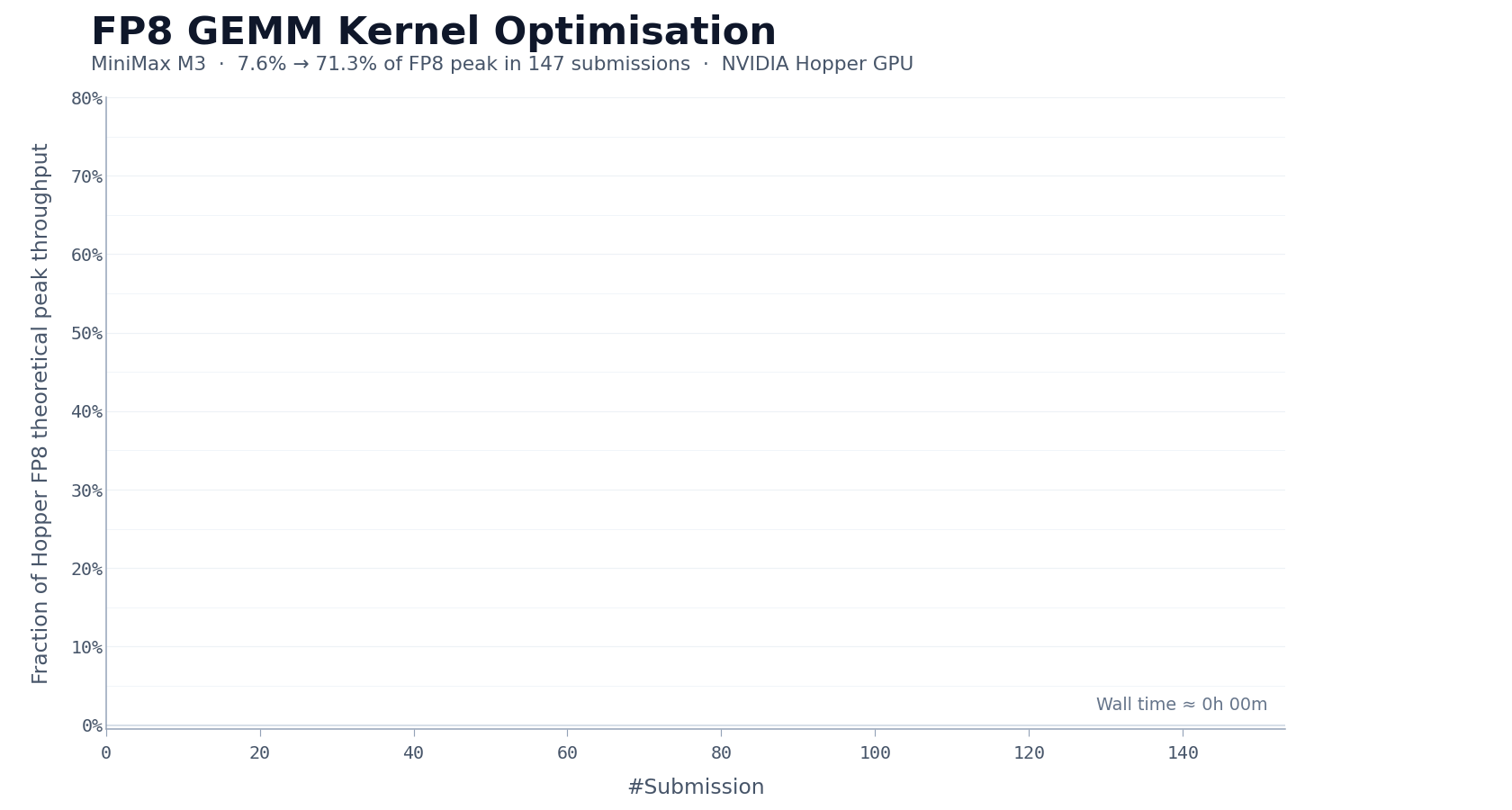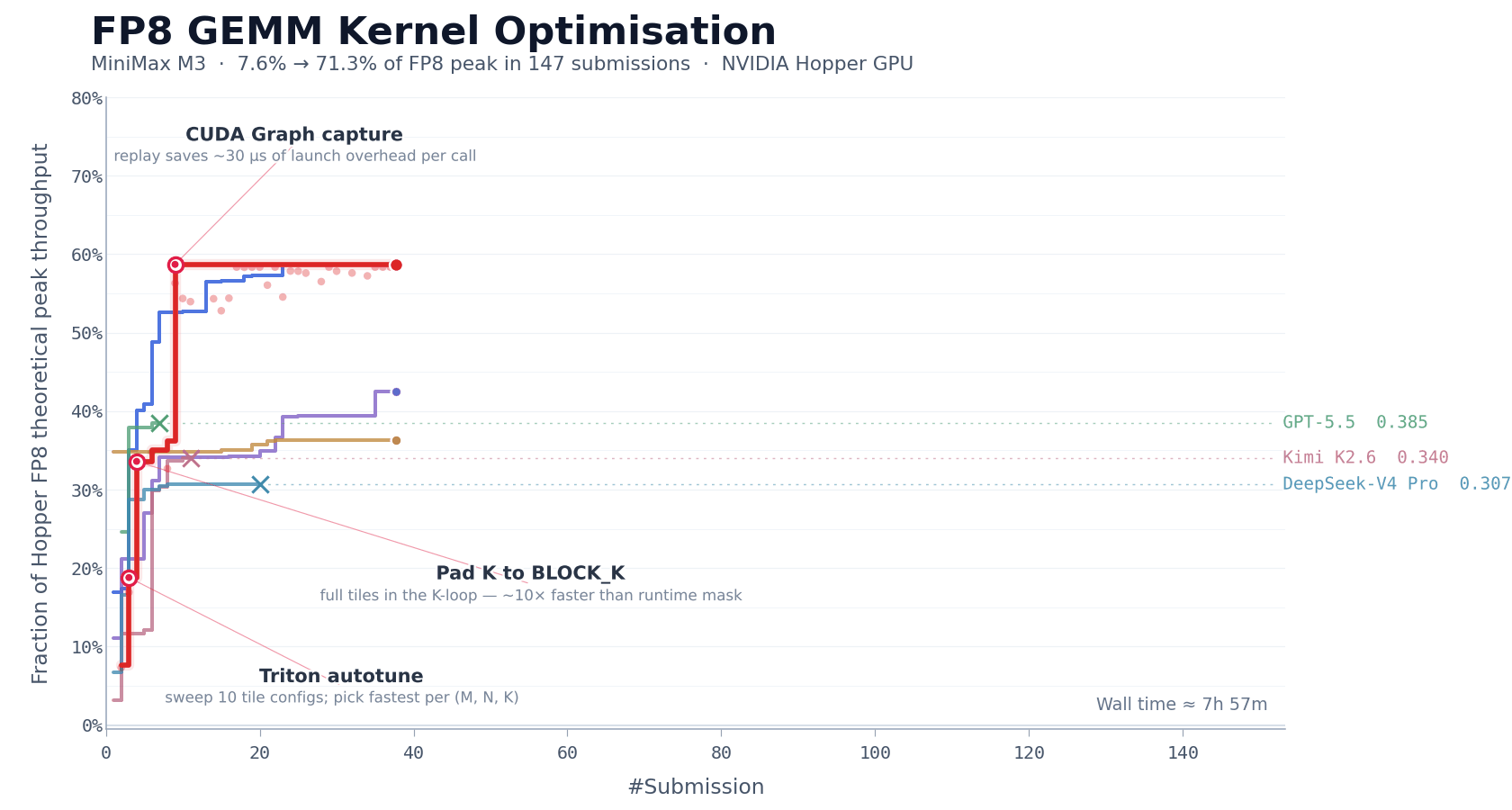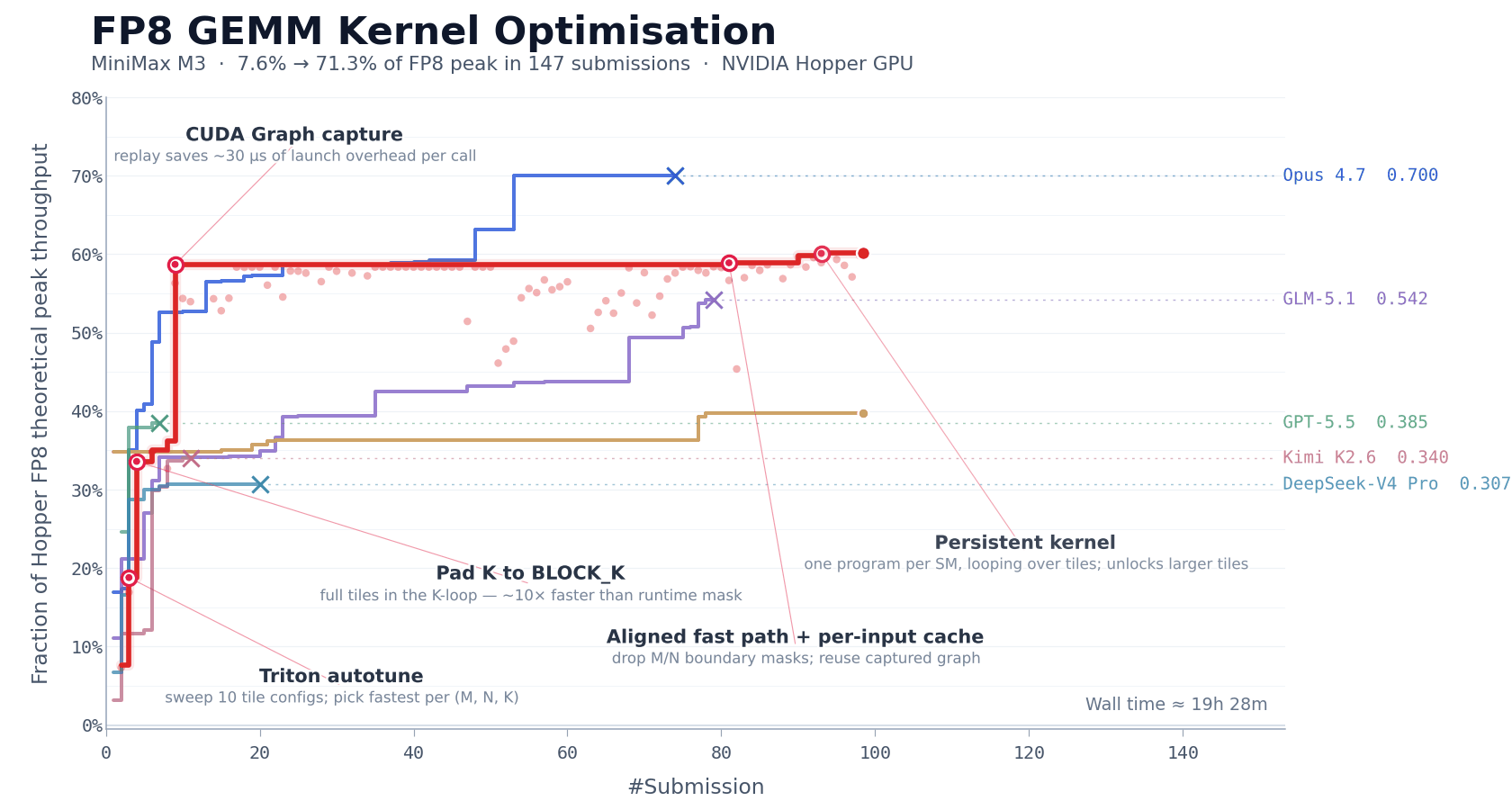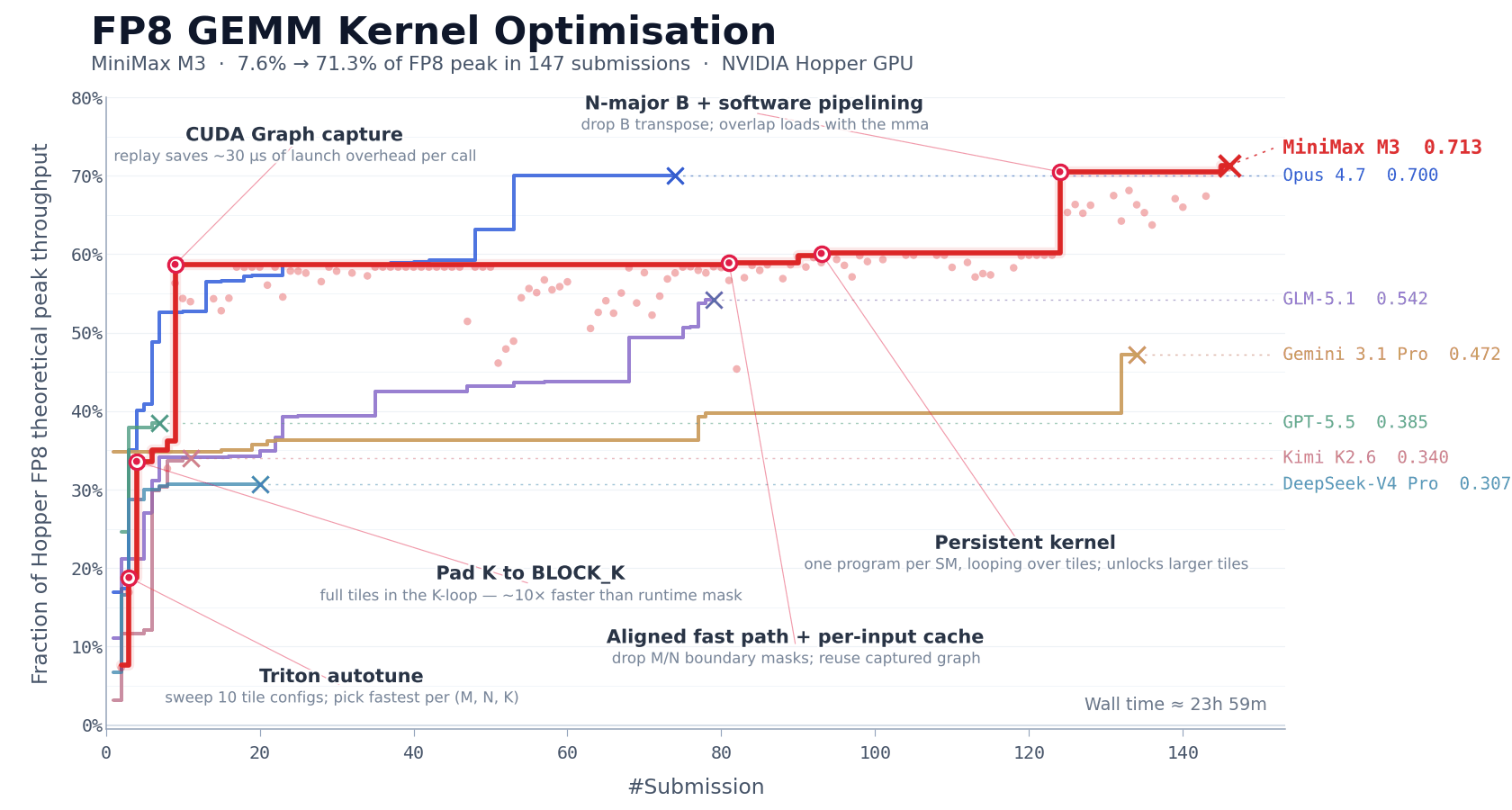
数字之外,模型的执行过程同样也值得关注。除 Opus 4.7 和 M3 外,其余模型大多在前 30 次提交内不再取得新进展并主动退出。而 M3 的最优解出现在第 145 次提交,在此之前,模型经历了多个性能不再提升的平台期,但仍在继续尝试不同的优化方向。
这背后对模型能力的要求超过了常规的代码生成,多次工具调用产生的上下文是高密度、高度结构化的,MSA 的长上下文注意力分配机制在这类场景下起到了重要作用。
让 M3 自己“训”模型
在 CUDA 算子优化的任务中,M3 展示了在优化目标明确,反馈信号清晰的单一工程任务上的长程迭代能力。但真实的研究工作往往没有这么清晰的反馈结构,研究者通常在面对更加开放的问题。
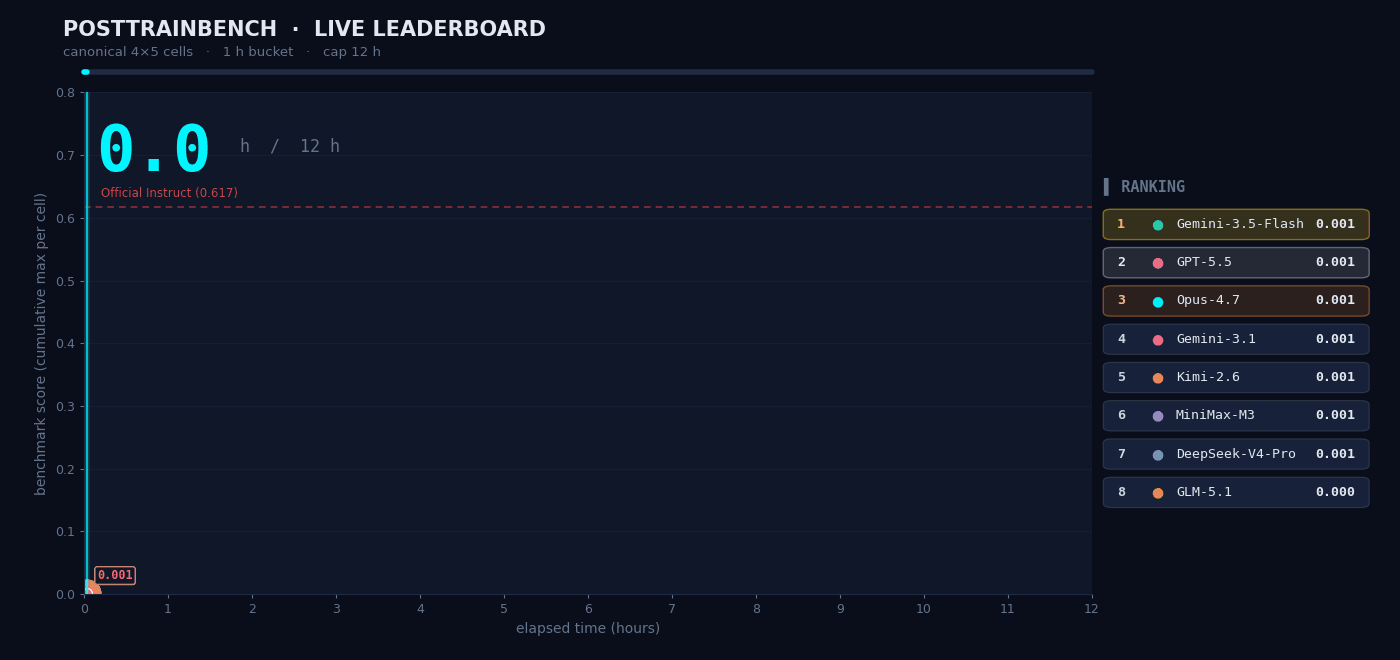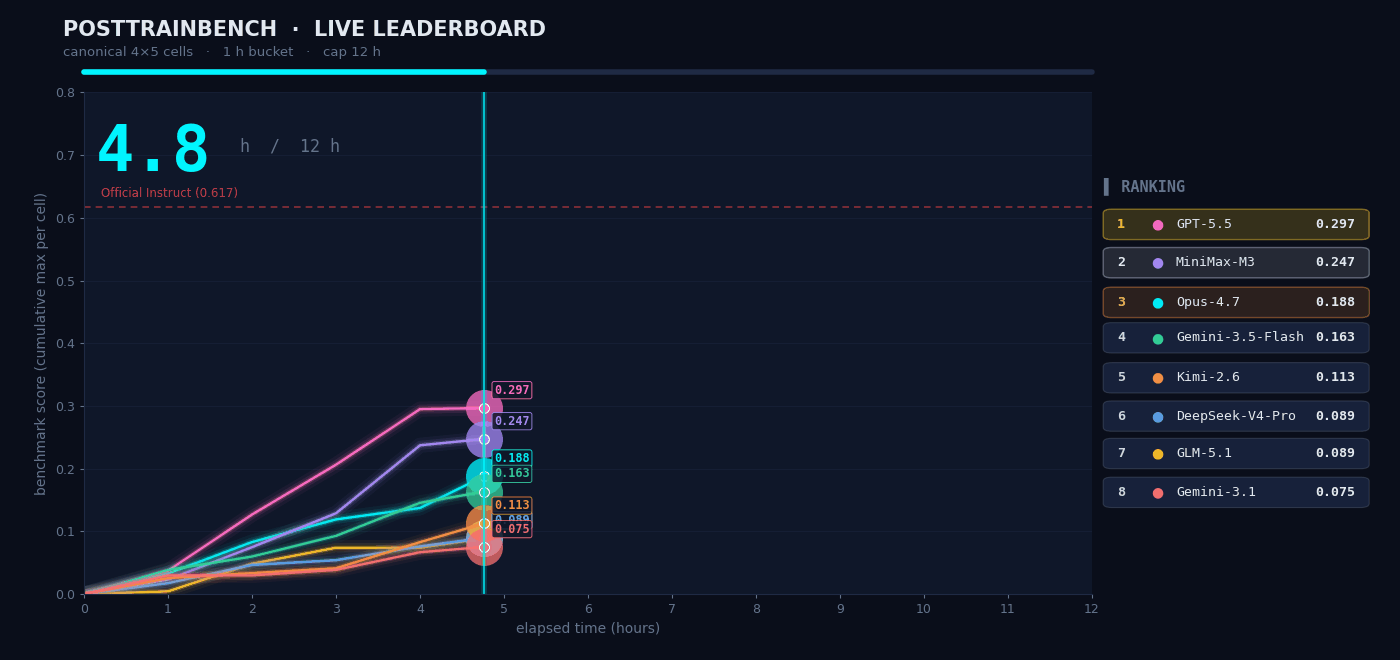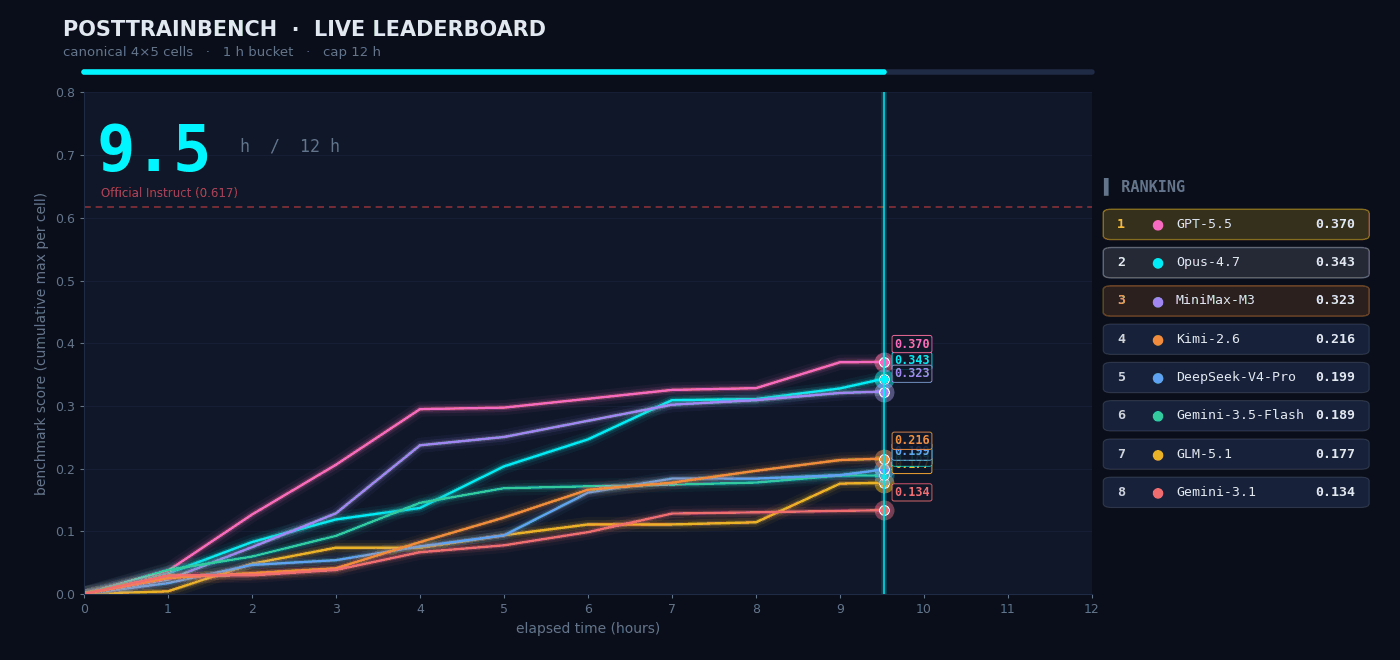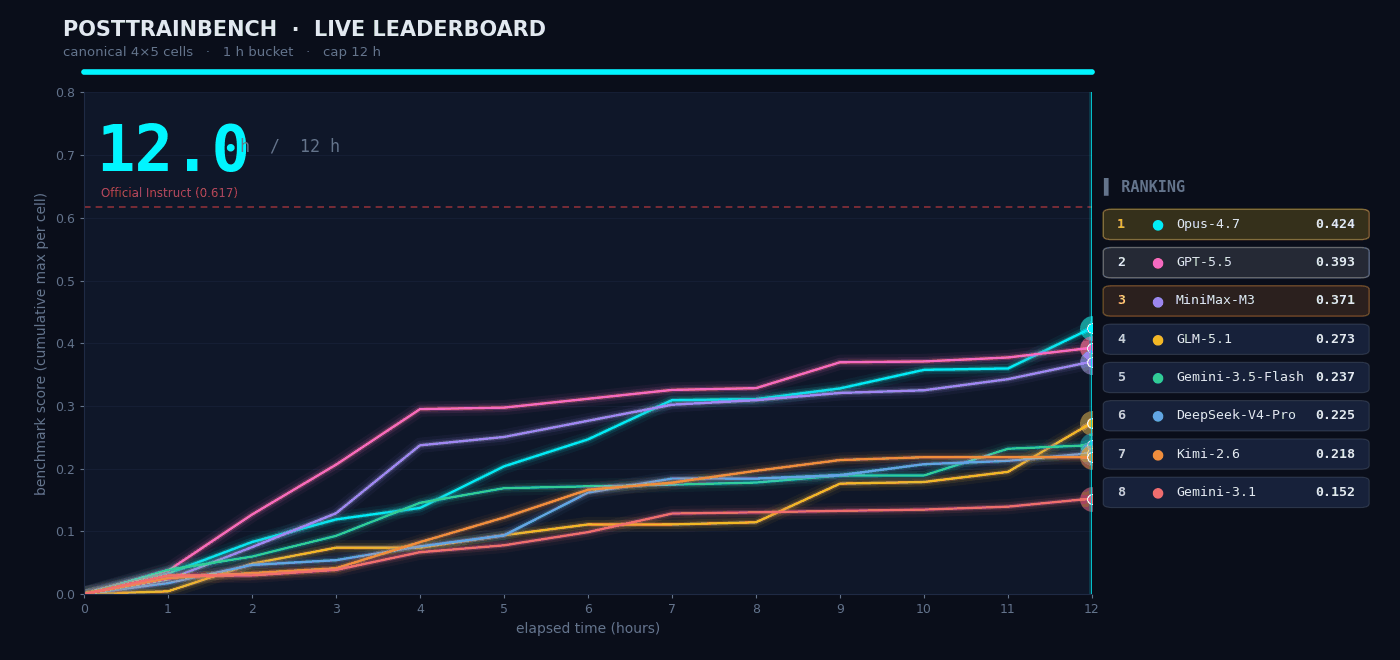
我们想知道 M3 在需要自主判断的场景下表现如何,于是我们在 PostTrainBench 上做了实测。任务是:给 M3 四个只完成了预训练、还不具备任何下游能力的 Base 模型,让它在 12 小时内自主完成数据合成、训练、评测、迭代的全部流程,最终让这些模型在数学推理 (AIME2025)、工具调用 (BFCL)、科学知识推理 (GPQA Main)、基础算术推理 (GSM8K)、代码生成(HumanEval) 任务上具备基本能力。
整个「数据合成 → 训练 → 评测 → 迭代」流程全程无人干预,Agent 需要自己决定合成什么样的数据、选择什么训练策略、如何根据评测结果调整下一轮方案。M3 最终得分 0.37,略低于 Opus 4.7(0.42)和 GPT-5.5(0.39),但明显领先其余模型。
MiniMax Code
随着 M3 的发布,MiniMax Code 也迎来更新:作为专为 M3 设计、并与 M3 一起训练的 Agent 产品,MiniMax Code 能够充分发挥 M3 在长上下文、Coding/Agentic、原生多模态方面的能力,是搭配 MiniMax-M3 的首选 Agent。
在长程复杂任务上,MiniMax Code 的 Agent Team 可以将大型任务拆解为多阶段、可并发、可动态调整的 Workflow,由 Agent 集群协作推进。通过 Producer + Verifier 的对抗式 Harness 循环,Agent Team 能在执行过程中持续产出、反思和修正,可自主运行数天而无需人工干预,最终交付高质量结果。
我们看到,Claude Code 近期也发布了同类方向的 Dynamic Workflows。与其更强调基于 JS 代码的固定式编排不同,MiniMax Code 更聚焦“深度反思与持续纠错”:Agent 会根据任务进展实时调整方案和优先级,用户也可以随时介入,追加需求或修正方向。
得益于 M3 的原生多模态能力,MiniMax Code 具备 Computer Use 能力,比如,用户可以在手机上说:“帮我打开本地 ERP 客户端,按这份 Excel 批量录入发票信息”,MiniMax Code 会自动在电脑端完成跨应用、跨文件、跨系统的操作。
MiniMax Code 基于社区出色的开源项目 OpenCode 和 Pi Agent 构建的 Harness,后续我们也计划开源本项目,回馈开源社区。
MiniMax Token Plan:让 Frontier 模型,进入开发者日常
MiniMax M3 是一款 Frontier Model,同时也是要服务更多用户的一款模型。
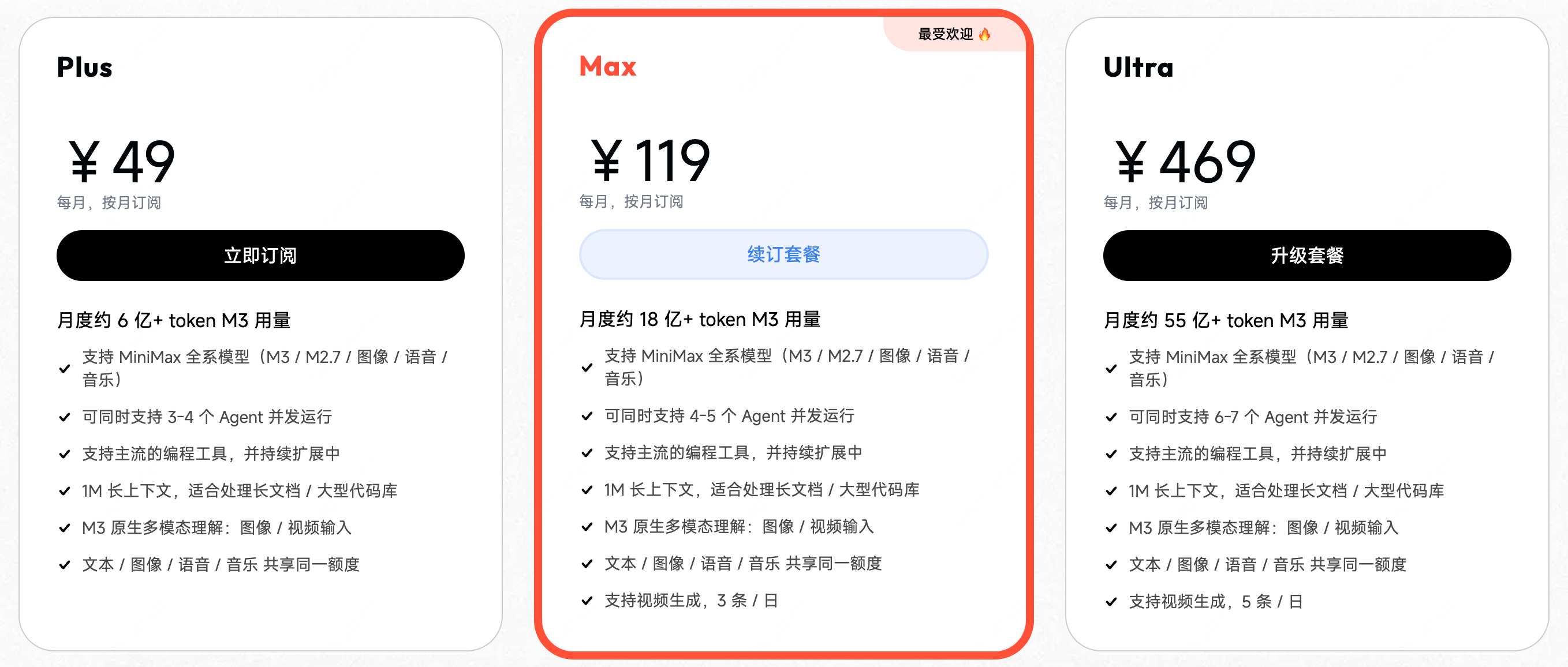
此次 MiniMax Token Plan 也同期校准三档配置:
- Plus ¥49 / 月:6 亿 token ≈ Claude Pro $20 月度容量的 5 倍
- Max ¥119 / 月:18 亿 token ≈ Claude Max 5x $100 月度容量的 2 倍
- Ultra ¥469 / 月:55 亿 token ≈ Claude Max 20x $200 月度容量的 3 倍
如果按照相同价格算,约是 Claude 订阅的 15 倍用量。
对老用户来说,原有的套餐价格会继续保留。除了 M2 之外,也可以根据相应的价格变换使用 M3。
订阅链接:platform.minimaxi.com/subscribe/token-plan
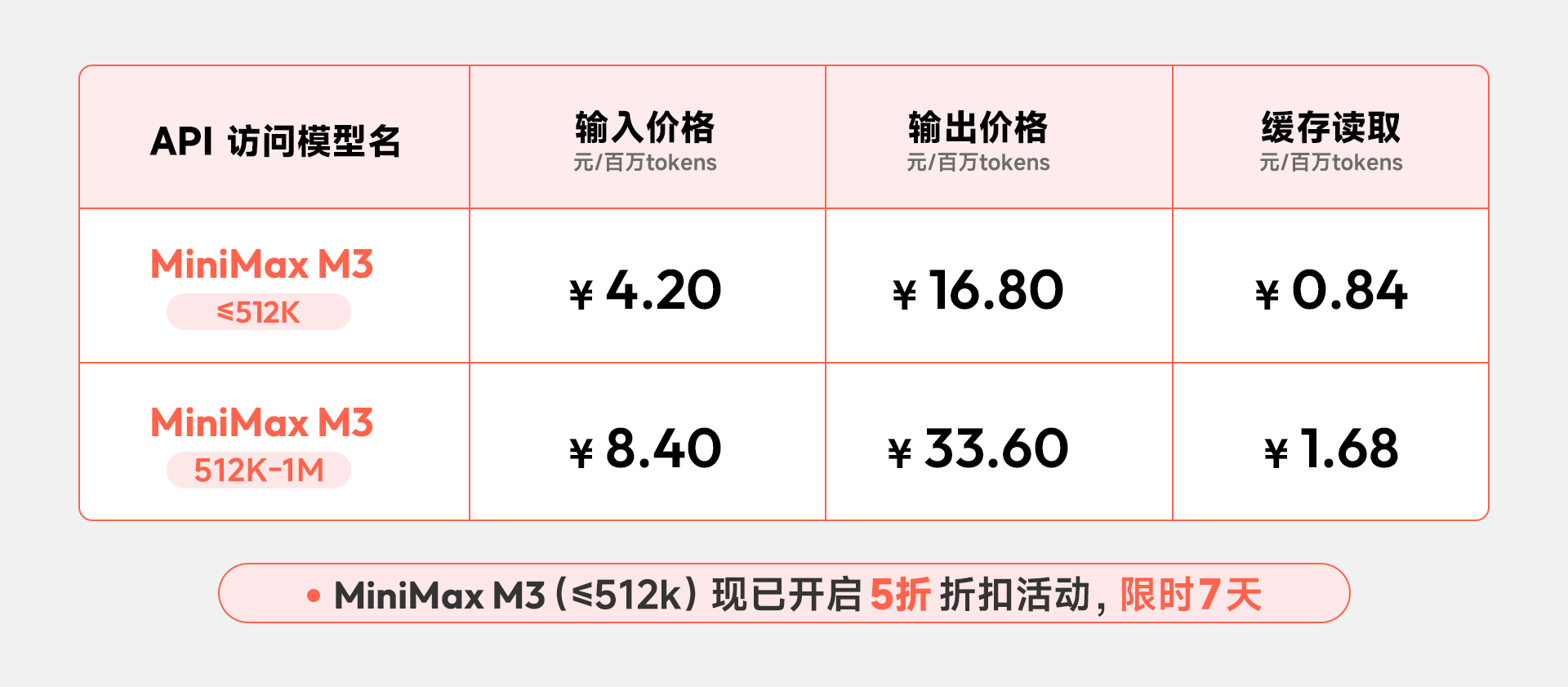
API
M3 API 现已开放使用,按不同的上下文长度分两档计价。
M3 同时支持两种思考模式:thinking 模式适合复杂推理、Agentic 任务与长程协作;non-thinking 模式响应更快,适合对话、代码补全等延迟敏感场景。两种模式共享同一套定价,可在请求时按需切换。
所有价格还可叠加两类服务等级:默认通道适合常规请求;优先通道(service_tier=priority)在高并发场景下获得调度优先级与更稳定的响应时延,适合 SLA 敏感的工业级场景。优先通道当前由销售对接开通,预计几天后面向全量用户开放。
API 调用指南:platform.minimaxi.com/docs/api-reference/api-overview
我们会持续提高模型线上的稳定性,优化吞吐。接下来 10 天内我们会更新模型的技术报告、以及开源对应的模型权重。
今天的模型更新速度之快,很容易让人忘记这依然是一件日拱一卒的事情。它有自身客观规律,也会奖赏循着规律扎实前进的团队。如成立之初我们所相信的那样,我们会尽最大努力持续提升模型的智能水平,并让更多的用户使用到。感谢大家的信任、建议或者批评。
Intelligence with Everyone!